Data management
Data sets
ATOM is designed to work around one single dataset: the one with which atom is initialized. This is the dataset you want to explore, transform, and use for model training and validation. ATOM differentiates three different data sets:
- The training set is usually the largest of the data sets. As the
name suggests, this set is used to train the pipeline. During
hyperparameter tuning, only the training set is used to fit and
evaluate the estimator in every call. The training set in the current
branch can be accessed through the
trainattribute. It's features and target can be accessed throughX_trainandy_trainrespectively. - The test set is used to evaluate the models. The model scores on
this set give an indication on how the model performs on new data. The
test set can be accessed through the
testattribute. It's features and target can be accessed throughX_testandy_testrespectively. - The holdout set is an optional, separate set that should only be
used to evaluate the final model's performance. Create this set when
you are going to use the test set for an intermediate validation step.
The holdout set is immediately set apart during initialization and is
not considered part of atom's dataset (the
datasetattribute only returns the train and test sets). The holdout set is left untouched until predictions are made on it, i.e., it does not undergo any pipeline transformations until the data set is requested for the first time. The holdout set is stored in atom'sholdoutattribute. See herean example that shows how to use the holdout data set.
The data can be provided in different formats. If the data sets are not specified beforehand, you can input the features and target separately or together:
- X
- X, y
Remember to use the y parameter to indicate the target column in X when
using the first option. If not specified, the last column in X is used as
the target. In both these cases, the sizes of the sets are defined using the
test_size and holdout_size parameters. Note that the splits are made
after the subsample of the dataset with the n_rows parameter (when not
left to its default value).
If you already have the separate data sets, provide them using one of the following formats:
- train, test
- train, test, holdout
- X_train, X_test, y_train, y_test
- X_train, X_test, X_holdout, y_train, y_test, y_holdout
- (X_train, y_train), (X_test, y_test)
- (X_train, y_train), (X_test, y_test), (X_holdout, y_holdout)
The input data is always converted internally to a dataframe
if it isn't one already. The column names should always be strings. If
they are not, atom changes their type at initialization. If no column
names are provided, default names are given of the form X[N-1],
where N stands for the n-th feature in the dataset.
Indexing
By default, atom resets the dataframe's index
after initialization and after every transformation in the pipeline.
To avoid this, specify the index parameter. If the dataset has an
'identifier' column, it is useful to use it as index for two reasons:
- An identifier doesn't usually contain any useful information on the target column, and should therefore be removed before training.
- Predictions of specific rows can be accessed through their index.
Warning
Avoid duplicate indices in the dataframe. Having them raises an error when initializing atom and may potentially lead to unexpected behavior if introduced later.
Sparse datasets
If atom is initialized using a scipy sparse matrix, it is converted internally to a dataframe of sparse columns. Read more about pandas' sparse data structures here. The same conversion takes place when a transformer returns a sparse matrix, like for example, the Vectorizer.
ATOM considers a dataset to be sparse if any of its columns is sparse. A dataset can only benefit from sparsity when all its columns are sparse, hence mixing sparse and non-sparse columns is not recommended and can cause estimators to decrease their training speed or even crash. Use the shrink method to convert dense features to sparse and the available_models method to check which models have native support for sparse matrices.
Click here to see an example that uses sparse data.
Warning
Estimators accelerated using sklearnex don't support sparse datasets.
Metadata
Metadata is data that an estimator, scorer, or CV splitter takes into account
if the user explicitly passes it as a parameter (besides X and y). ATOM
offers native integration with sklearn's metadata routing
system. Use the metadata parameter to pass metadata
to atom. This metadata is then automatically propagated to all relevant estimators,
scorers, and CV splitters. The parameter accepts a dictionary with keys
'groups' and/or 'sample_weight'. See the metadata example
for a quick tutorial.
groups
Groups are used primarily in cross-validation techniques that need to account
for grouped data. The groups parameter is particularly important in situations
where the data is not independent, such as when there are multiple measurements
from the same subject or when the data is organized in clusters that should not
be split across different folds.
Warning
- Groups are unavailable for forecast tasks.
- A group can only be present in one data set, thus a group present in the training set is not validated upon, and a group present in the test set is not used for training. It's highly recommended to use a model's cross_validate method to validate on all groups and so avoid potential biases.
sample_weight
Sample weights are numerical values assigned to individual data points in a dataset. They indicate the relative importance or frequency of each data point. Sample weights are used to:
- Handle imbalanced datasets: In classification problems, certain classes may be underrepresented. Sample weights can give more importance to these minority classes during model training.
- Correct for sampling bias: If the data collected does not represent the population well, weights can adjust the influence of different samples to better reflect the actual distribution.
- Emphasize certain samples: In cases where some samples are more reliable or significant than others, weights can be used to give more prominence to these samples in the analysis.
- Aggregation and averaging: When computing statistics, weighted averages can be calculated to account for the varying importance of samples.
Multioutput tasks
Multioutput is a task where there are more than one target column, i.e.,
the goal is to predict multiple targets at the same time. When providing
a dataframe as target, use the y parameter. Providing
y without keyword makes ATOM think you are providing train, test (see
the data sets section).
Task types
ATOM recognizes four multioutput tasks.
Note
Combinations of binary and multiclass target columns are treated as multiclass-multioutput tasks.
Multilabel
Multilabel is a classification task, labeling each sample with m labels
from n_classes possible classes, where m can be 0 to n_classes inclusive.
This can be thought of as predicting properties of a sample that are not
mutually exclusive.
For example, prediction of the topics relevant to a text document. The
document may be about one of religion, politics, finance or education,
several of the topic classes or all of the topic classes. The target
column (atom.y) could look like this:
0 [politics]
1 [religion, finance]
2 [politics, finance, education]
3 []
4 [finance]
5 [finance, religion]
6 [finance]
7 [religion, finance]
8 [education]
9 [finance, religion, politics]
Name: target, dtype: object
A model can not directly ingest a variable amount of target classes. Use
the clean method to assign a binary output to
each class, for every sample. Positive classes are indicated with 1 and
negative classes with 0. It is thus comparable to running n_classes
binary classification tasks. In our example, the target (atom.y) is
converted to:
education finance politics religion
0 0 0 1 0
1 0 1 0 1
2 1 1 1 0
3 0 0 0 0
4 0 1 0 0
5 0 1 0 1
6 0 1 0 0
7 0 1 0 1
8 1 0 0 0
9 0 1 1 1
Multiclass-multioutput
Multiclass-multioutput (also known as multitask classification) is a classification task which labels each sample with a set of non-binary properties. Both the number of properties and the number of classes per property is greater than 2. A single estimator thus handles several joint classification tasks. This is both a generalization of the multilabel classification task, which only considers binary attributes, as well as a generalization of the multiclass classification task, where only one property is considered.
For example, classification of the properties "type of fruit" and "colour" for a set of images of fruit. The property "type of fruit" has the possible classes: "apple", "pear" and "orange". The property "colour" has the possible classes: "green", "red", "yellow" and "orange". Each sample is an image of a fruit, a label is output for both properties and each label is one of the possible classes of the corresponding property.
Multioutput regression
Multioutput regression predicts multiple numerical properties for each sample. Each property is a numerical variable and the number of properties to be predicted for each sample is >= 2. Some estimators that support multioutput regression are faster than just running n_output estimators.
For example, prediction of both wind speed and wind direction, in degrees, using data obtained at a certain location. Each sample would be data obtained at one location and both wind speed and direction would be output for each sample.
Multivariate
Multivariate is the multioutput task for forecasting. In this case, we try to forecast more than one time series at the same time.
Although all forecasting models in ATOM support multioutput tasks (thus
have the native multioutput=True flag), we still differentiate two types
of models:
- The "genuine multioutput" models apply forecasts where every prediction
of endogenous (
y) variables will depend on values of the other target columns. - The rest of the models apply an estimator per column, meaning that forecasts
will be made per endogenous variable, and not be affected by other variables.
To access the column-wise estimators, use the estimator's
forecasters_parameter, which stores the fitted forecasters in a dataframe.
Tip
Use sktime's get_tags() method to check if an estimator is "genuine
multioutput", e.g. atom.tbats.estimator.get_tags(). Search for the
scitype:y key in the response. If the value is 'univariate', the
estimator is genuine multioutput, and if 'multivariate', it isn't.
Read more about time series tasks here.
Native multioutput models
Some models have native support for multioutput tasks. This means that
the original estimator is used to make predictions directly on all the
target columns. Read in the model selection section how to get an
overview of all models and their tags, including the native_multioutput.
Non-native multioutput models
The majority of the models don't have integrated support for multioutput tasks. However, it's possible to still use them for such tasks, wrapping them in a meta-estimator capable of handling multiple target columns. For non-native multioutput models, ATOM does so automatically. For multilabel tasks, the meta-estimator is:
And for multiclass-multioutput and multioutput regression, the meta-estimators are respectively:
Warning
Currently, scikit-learn metrics do not support multiclass-multioutput classification tasks. In this case, ATOM calculates the mean of the selected metric over every target.
Tip
- Set the
native_multilabelornative_multioutputparameter in ATOMModel equal toTrueto ignore the meta-estimator for custom models. - Check out the multilabel classification and multioutput regression examples.
Branches
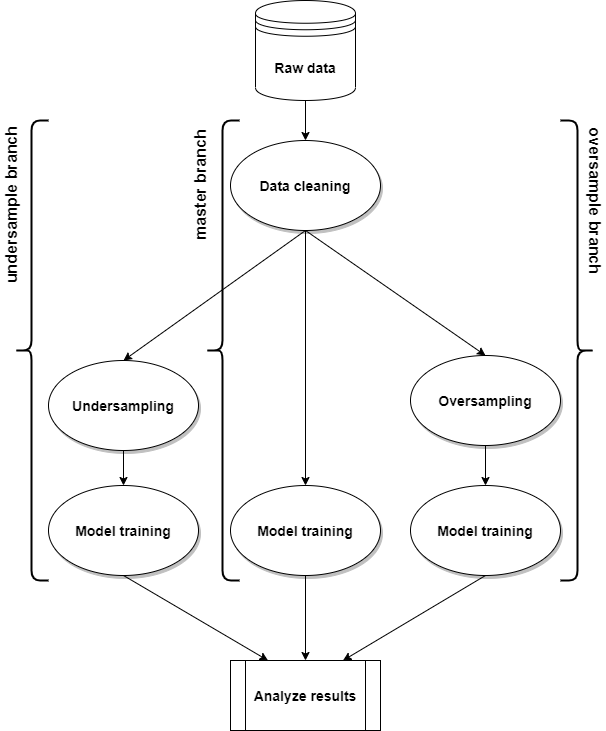
You might want to compare how a model performs on a dataset transformed through multiple pipelines, each using different transformers. For example, on one pipeline with an undersampling strategy and the other with an oversampling strategy. To be able to do this, ATOM has a branching system.
The branching system helps the user to manage multiple data pipelines
within the same atom instance. Branches are created and accessed
through atom's branch property. A branch contains a specific pipeline,
the dataset transformed through that pipeline, and all data and utility
attributes that refer to that dataset. Transformers and models called
from atom use the dataset in the current branch, as well as data
attributes such as atom.dataset. It's not allowed to change the data
in a branch after fitting a model with it. Instead, create a new branch
for every unique pipeline.
By default, atom starts with one branch called "main". To start a new
branch, set a new name to the property, e.g., atom.branch = "undersample".
This creates a new branch from the current one. To create a branch from any
other branch type "_from_" between the new name and the branch from which
to split, e.g., atom.branch = "oversample_from_main" creates
branch "oversample" from branch "main", even if the current branch is
"undersample". To switch between existing branches, just type the name of
the desired branch, e.g., atom.branch = "main" brings you back
to the main branch. Note that every branch contains a unique copy of the
whole dataset! Creating many branches can cause memory issues
for large datasets.
See the Imbalanced datasets or Feature engineering examples for branching use cases.
Warning
Always create a new branch if you want to change the dataset after fitting
a model! Forcing a data change through the data property's @setter can
cause unexpected model behavior and break down the plotting methods.
Memory considerations
An atom instance stores one copy of the dataset for each branch (this doesn't include the holdout set, which is only stored once), and one copy of the initial dataset with which the instance is initialized. This copy of the original dataset is necessary to avoid data leakage during hyperparameter tuning and for some specific methods like cross_validate and reset. It's created as soon as there are no branches in the initial state (usually after calling the first data transformation). If the dataset is occupying too much memory, consider using the shrink method to convert the dtypes to their smallest possible matching dtype.
When working with large datasets and multiple branches, it becomes impossible
to store all branches in memory at the same time. To avoid out-of-memory errors,
use atom's memory parameter. If not False, atom
saves the data of inactive branches as well as the original branch at the
specified location (in a directory called joblib, the name of the underlying
library managing the caching), maintaining only the current active branch in
memory. This mechanism results in a slight drop in performance because of the
I/O overhead, but can save a lot of memory. Additionally, the memory's location
is also used to cache the output of the fit and transform methods of steps
in the pipeline. See here an example using the
memory parameter.
Apart from the dataset itself, a model's metric scores and shap values are also stored as attributes of the model to avoid having to recalculate them every time they are needed. You can delete all these attributes using the clear method in order to free some memory before saving atom.
Data transformations
Performing data transformations is a common requirement of many datasets before they are ready to be ingested by a model. ATOM provides various classes to apply data cleaning and feature engineering transformations to the data. This tooling should be able to help you apply most of the typically needed transformations to get the data ready for modeling. For further fine-tuning, it's also possible to transform the data using custom transformers (see the add method) or through a function (see the apply method). Remember that all transformations are only applied to the dataset in the current branch.
Row and column selection
Many methods in atom contain the rows or columns parameter to select a
subset of the dataset. Examples are the evaluate
and save_data methods for rows, and the
distributions and shrink
methods for columns. All data cleaning and feature engineering methods
use the columns parameter to apply the transformation only to that selection
of columns, and all prediction methods use the rows parameter
to make predictions on that selection of rows.
As you can see, these two parameters are very important and shared across many methods in atom. Rows and columns can be selected in multiple ways. The check is performed in the order described hereunder:
- By actual dataset, e.g.,
rows=atom.testis equal torows="test". - By range or slice, e.g.,
rows=range(100)to select the first 100 rows from the dataset orrows=slice(20, 100)to select rows 20 to 99. - By exact name, e.g.,
rows=["row1", "row2"]to select rows with indicesrow1androw2orcolumns=["col1", "col2"]to select columnscol1andcol2. It's also possible to use the+sign to select multiple rows or columns, e.g.,columns="col1+col2is the same ascolumns=["col1", "col2"]. - By position, e.g.,
rows=[0, 1, 2]to select the first three rows. - By name of the data set (only for rows), e.g.,
rows="train"to select all rows in the training set, orrows="test+holdout"to select all rows in the test and holdout sets. Valid data sets aredataset,train,testandholdout. - By dtype (only for columns), e.g.,
columns="number"to select only numerical columns. See pandas' user guide. - By regex match, e.g.,
columns="mean_.*"to select all columns starting withmean_. - Excluding instead of including using the
!sign, e.g.columns="!col1"to select all columns exceptcol1. You can also exclude multiple rows or columns like thiscolumns=["!col1", "!col2"]or thiscolumns="!col1+!col2". It's also possible to exclude data sets for row selection, e.g.,columns="!train"or dtypes for column selection, e.g.,columns="!number". Note that if a column name starts with!, the selection of that name will take priority over exclusion. Rows and columns can only be included or excluded, and not both at the same time. For example, this selection raises an exceptioncolumn=["col1", "!col2"].
Additionally, the forecast horizon (parameter fh) in forecasting tasks
can be selected much in the same way as rows, where the horizon is inferred
as the index of the row selection. Note that, contrary to sktime's API but for
consistency with the rest of ATOM's API, atom's fh starts with the training set,
i.e., selecting atom.nf.predict(fh=range(5)) forecasts the first 5
rows of the training set, not the test set. To get the same result as sktime, use
a ForecastingHorizon object, e.g., atom.nf.predict(fh=ForecastingHorizon(range(5))).
Info
In some plotting methods, it's possible to plot separate
lines for different subsets of the rows. For example, to compare the results
on the train and test set. For these cases, either provide a sequence to the
rows parameter for every line you want to draw, e.g., atom.plot_roc(rows=("train", "test")),
or provide a dictionary where the keys are the names of the sets (used in the
legend) and the values are the corresponding selection of rows, selected using
any of the aforementioned approaches, e.g, atom.plot_roc(rows={"0-99": range(100), "100-199": range(100, 200}).
Note that for these methods, using atom.plot_roc(rows="train+test"),
only plots one line with the data from both sets. See the
advanced plotting example.
Data engines
ATOM is mostly built around sklearn (and sktime for time series
tasks), and both these libraries use numpy as their computation backend. Since
atom relies heavily on column names, it uses pandas (which in turn uses numpy)
as its data backend. However, for the convenience of the user, it implements
several data engines, that wraps the data in a different type when called by the
user. This is very similar to sklearn's set_output behaviour, but ATOM
extends this to many more data types. For example, selecting the polars data
engine, makes atom.dataset return a polars dataframe and atom.winner.predict(X)
return a polars series. See here an example notebook.
The data engine can be specified through the engine
parameter, e.g. engine="pyarrow" or engine={"data": "pyarrow","estimator": "sklearnex"} to combine it with an [estimator engine][estimator acceleration].
ATOM integrates the following data engines:
- numpy: Transform the data to a
numpyarray. - pandas: Leave the dataset as a
pandasobject. This is the default engine, that leaves the data unchanged. - pandas-pyarrow: Transform the data to
pandaswith thepyarrowbackend. Read more in pandas' user guide. - polars: The polars library is a blazingly fast dataframe library implemented in Rust and based on Apache Arrow. Transforms the data to a polars dataframe or series.
- polars-lazy: This engine is similar to the
polarsengine, but it returns a pl.LazyFrame instead of a pl.pd.DataFrame. - pyarrow: PyArrow is a cross-language, platform-independent, in-memory data format, that provides an efficient and fast way to serialize and deserialize data. the data is transformed to a pa.Table or pa.Array.
- modin: The modin library is a multi-threading, drop-in replacement for pandas, that uses Ray as backend. Transform the data to a modin dataframe or series.
- dask: The dask library is a powerful Python library for parallel and distributed computing. Transform the data to a dask dataframe or dask series.
- pyspark: The pyspark library is the Python API for Apache Spark. Transform the data to a pyspark dataframe or pyspark series.
- pyspark-pandas: Similar to the
pysparkengine, but it returns pyspark objects with the pandas API.
Note
It's important to realize that, within atom, the data is still processed using pandas (with the numpy backend). Only when the data is returned to the user, it is transformed to the selected format.