Introduction
There is no magic formula in data science that can tell us which type of machine learning estimator in combination with which pipeline will perform best for a given raw dataset. Different models are better suited for different types of data and different types of problems. You can follow some rough guide on how to approach problems with regard to which model to try, but these are incomplete at best.
During the exploration phase of a machine learning project, a data scientist tries to find the optimal pipeline for his specific use case. This usually involves applying standard data cleaning steps, creating or selecting useful features, trying out different models, etc. Testing multiple pipelines requires many lines of code, and writing it all in the same notebook often makes it long and cluttered. On the other hand, using multiple notebooks makes it harder to compare the results and to keep an overview. On top of that, refactoring the code for every test can be quite time-consuming. How many times have you conducted the same action to pre-process a raw dataset? How many times have you copy-and-pasted code from an old repository to re-use it in a new use case?
Although best practices tell us to start with a simple model and build up to more complicated ones, many data scientists just use the model best known to them in order to avoid the aforementioned problems. This can result in poor performance (because the model is just not the right one for the task) or in inefficient management of time and computing resources (because a simpler/faster model could have achieved a similar performance).
ATOM is here to help solve these common issues. The package acts as a wrapper of the whole machine learning pipeline, helping the data scientist to rapidly find a good model for his problem. Avoid endless imports and documentation lookups. Avoid rewriting the same code over and over again. With just a few lines of code, it's now possible to perform basic data cleaning steps, select relevant features and compare the performance of multiple models on a given dataset, providing quick insights on which pipeline performs best for the task at hand.
It is important to realize that ATOM is not here to replace all the work a data scientist has to do before getting his model into production. ATOM doesn't spit out production-ready models just by tuning some parameters in its API. After helping you determine the right pipeline, you will most probably need to fine-tune it using use-case specific features and data cleaning steps in order to achieve maximum performance.
Example steps taken by ATOM's pipeline:
- Data Cleaning
- Handle missing values
- Encode categorical features
- Detect and remove outliers
- Balance the training set
- Feature engineering
- Create new non-linear features
- Select the most promising features
- Train and validate multiple models
- Apply hyperparameter tuning
- Fit the models on the training set
- Evaluate the results on the test set
- Analyze the results
- Get the scores on various metrics
- Make plots to compare the model performances
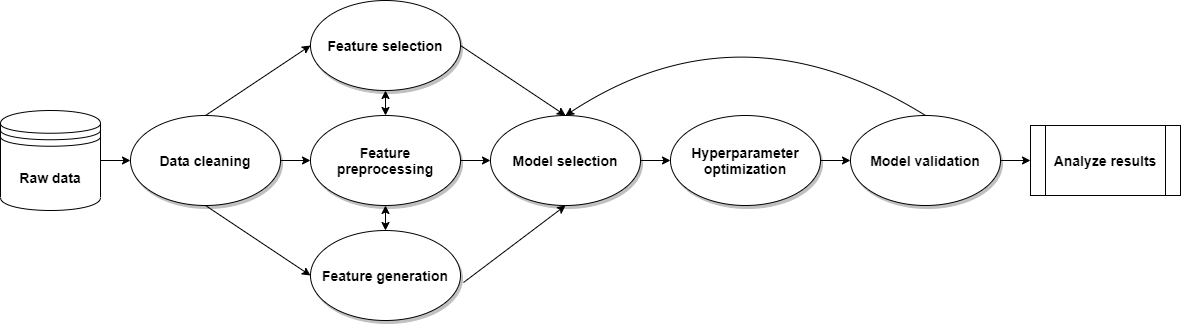
<figcaption>Figure 1. Diagram of a possible pipeline created by ATOM.</figcaption>